こんにちは。MACです!!
今年度の大きな目標を3つ紹介します。
- 海外と日本をオンラインで繋ぎながら”ものづくり”をすること。
- 韓国語、中国語を日常会話レベルまで使えるようにすること。
- 資格を取ること。(ショベルカー、ITパスポート、スポーツ指導員、陸上審判)
おまけ…
つい先日善光寺仲見世にオープンした『抹茶館』に一人でパフェを食べに行ってきました!(笑)
2階の席からは善光寺が☆彡(晴れていれば)

以上で終わります。雑ですみませんm(_ _)m

-つくる学びを科学する-
こんにちは。MACです!!
今年度の大きな目標を3つ紹介します。
おまけ…
つい先日善光寺仲見世にオープンした『抹茶館』に一人でパフェを食べに行ってきました!(笑)
2階の席からは善光寺が☆彡(晴れていれば)
以上で終わります。雑ですみませんm(_ _)m
最近話題のChatCPTを使ってみました。とても面白かったのでみなさんに是非使っていただきたいと思ったので、ブログに残していきます!
ChatGPTは簡単に説明すると「とっても優れたチャットAI」です。
今回はChatGPTについての情報をChatGPTに聞いてみました。

私はこれから、ChatGPTについての記事を書こうとしています。そこで、ChatGPTについて教えてください

ChatGPTはOpenAIによって開発された大規模な自然言語処理モデルです。GPTとは「Generative Pre-trained Transformer」の略で、事前学習されたトランスフォーマーモデルを用いて、テキスト生成、文章分類、文章の質問応答、文章の要約などの自然言語処理タスクを実行できます。ChatGPTは、コミュニケーションエージェント、自動チャットボット、自動翻訳など、多岐にわたるアプリケーションで利用されています。

もっと詳しく教えて
ChatGPTは、自然言語処理の分野で最先端の技術の一つであるトランスフォーマーというニューラルネットワークを用いた言語モデルです。トランスフォーマーは、入力の前後関係を考慮することで文章の意味を理解し、文章の生成や分類などのタスクを行うことができます。
ChatGPTは、トランスフォーマーを使って、大量のテキストデータを事前に学習することで、自然言語処理の様々なタスクに高い精度で対応できるようになります。ChatGPTは、最新のバージョンである「GPT-3」では、1兆個以上のパラメータを持ち、広範な自然言語タスクに対応することができます。
ChatGPTは、多数の自然言語処理タスクに応用されています。例えば、会話型AIアプリケーション、自動翻訳、文章の生成や要約、文章の感情分析などが挙げられます。ChatGPTの性能は非常に高く、人工的に生成された文章と区別がつかないほどの自然な文章を生成することもできます。これにより、人工知能が人間とのコミュニケーションに利用される可能性が高まっています。
ChatGPTは大量のテキストデータから学習されたデータを用いて、入力前後の関係を単語ではなく、文章で理解し、最適な文章の生成や分類などを行うAIと言うことが分かります!
実際にも現在の取り組みとして、
が試験的に行われ、大きな実績を残しています。大量のテキストデータから学習されたデータはとても恐ろしいですね。
AIの普及によって、自分で考えるよりもAIを使った方が「早く・確実・楽」という子どもが利用するメリットがそろっています。しかしながら、AIも誤った情報を与えることがあることが、明言されています。このような場合に「本当にその情報が正しいのか?」と疑う力・見抜く力が求められると私は思います。また、簡単な情報はより手に入りやすくなるので、「知識を活用して、考える時間が学校の中で増えていくのではないか」と思います。
しかしながら、AIを活用していく場面は増えていくと考えられます。現在社会問題にもなっている教師の長時間労働についてですが、形式的な事務の業務や書類作成などはAIの方が確実で早いです。そのような使い方をしていくことで学校現場に一本の灯りが灯るのではないかと私は思いました。
児童生徒はもちろん、教師も「AIに全てを委ねるのではなく、AIを利用し、考えるプロセスを大切にする」ことが今後は重要視されていくのではないかと私はChatGPTを利用しながら考えました。
このChatGPTはAPIやβ版で絵も描けるとのことなので、是非使ってみたいなと思いました!
明けましておめでとうございます。今年もよろしくおねがいします。
このブログでは昨年の振り返りと今年の目標についてのブログにしていきたいと思います。
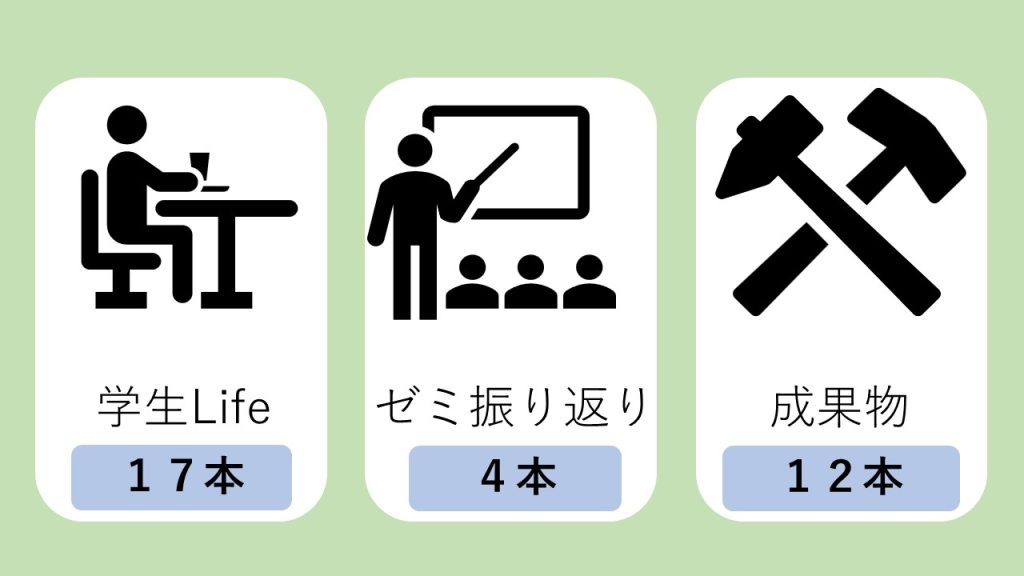
合計33本でした!
後期から始めたゼミの振り返りはとても読みごたえのあるブログになっています。お互いが振り返ることで、別の視点でも考えることができ、実際どのように自分のものにしていくか、今後どのようにしていくかが述べられていていました。研究室の活動を残しつつ、高校生にも大学の活動について知っていただけるように続けていきたいと思います!
magnetが書いたPythonでスクレイピングを実際に行ったブログが第3位でした!
授業の振り返りで行った内容をブログにしました。実際のPythonのコードも公開しています!コメントも丁寧にあるのが印象的でした。スクレイピングは便利な半面、使い方を間違えるとサイトに負荷をかけるものなので注意も必要ですね!
AIを使った画像生成ツールのブログが第2位でした!
大学の授業でAIについて学習したのをきっかけに、AIが活用されているツールを紹介したブログになります。キーワードをもとにAIが自動で画像を生成するツールで、とても話題になりました!現在ではたくさんのツールが出てきました。SNSでも手軽にAIの画像生成が使われていて、私達の生活の周りにAIが近づいているように感じます。
教材としても使いやすいものになるので、高校の情報や技術科の教材としての活用も近い未来に行われるかもしれないですね
Pythonで行うLINEAPIの紹介を行ったブログが第1位でした!
Pythonの学習で最初に何をしたらいいのかわからない方にとてもおすすめなツールです。とても簡単に実装をすることができます。
最近では、Youtubeでも解説している動画もたくさんあるので動画を見ながら学習を行うこともアリです!
昨年度の上半期は授業の振り返りを行ったブログが多く、下半期はゼミの振り返りを行ったブログが投稿されました。現在のゼミのメンバーは7人もいるにも関わらず、下半期はかなりサボってしまいました。反省の限りです。上級生としてもっとできたことがあったのではないかと思ってしまいます。来年度もこのような事態にならないように、原因の分析と対策を行っていきたいです。
これらを目標に一年間行っていきたいと思います!
また、より多くの方に知っていただけるようにWordPressの理解を深めていくことも必要になっていくと思います。学び続けることを忘れず、前進し続けたいと思います!
今年も小倉研究室をよろしくお願いします。
こんにちは!magです。
今回は成果物として研究室の看板を紹介したいと思います!
まずはきっかけの紹介です!
ある日ふと他の研究室にお邪魔する際に
他の研究室の入り口を見てみると、
個性豊かな看板が貼り付けられていました……
そういえばうちには何も飾られていないなあと思い、
じゃあ作っちゃえば良いじゃない!!と
思い立ちました。
小倉先生に伺ったところ、「自由に作っていいよ!」とのことだったので
自由に作らせていただきました笑
そうなるとまずは構想からしなくてはなりません。
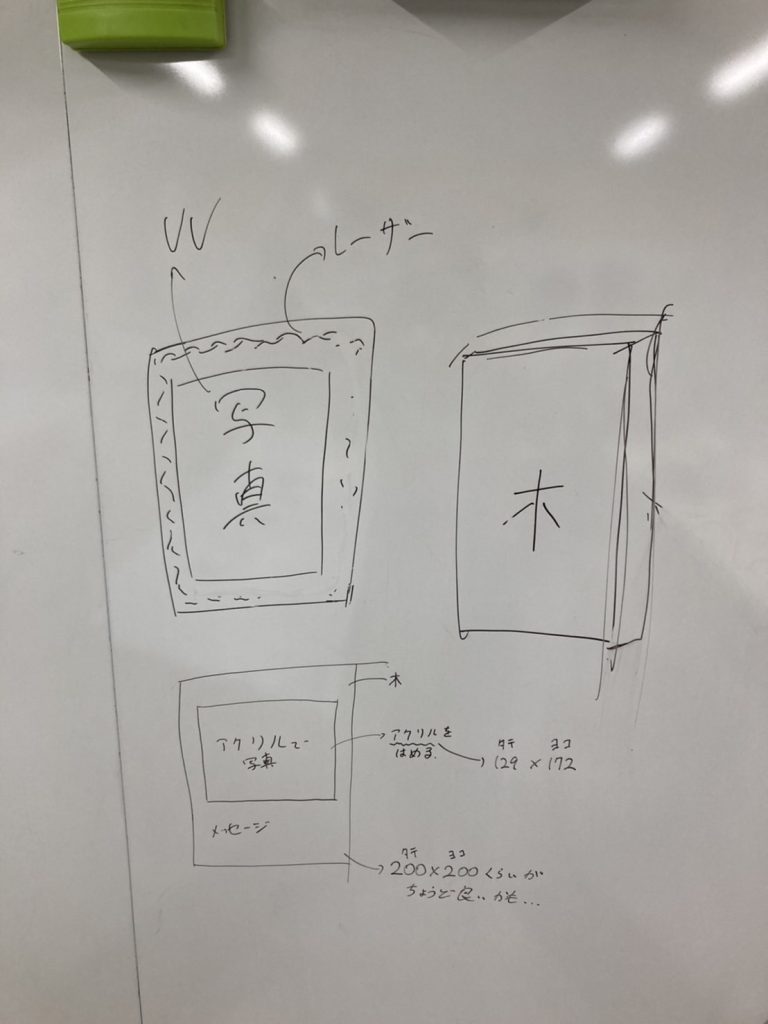

いろいろ、思考を巡らせました。
小倉先生にも構想を伺って
その後3DプリンタやUVプリンタを使って
フォントや、印字の具合、色の出方などなど試行錯誤を重ねていきました。



何度も下準備を重ねた上で、本番行きましょう!


まずは良さげな木材と頑丈そうなプラ板を用意して、
いよいよ下準備したデータたちを、印刷していきます……ドキドキ……
そして完成品がこちらです!

左上のマスコットキャラクターがとっても可愛いですね^^
真ん中のスペースには、集合写真なんかが入れられたら良いなあなんて思っています。
これをオープンキャンパスの時に見て「明るい雰囲気の研究室なんだなあー」って
思って帰ってもらうだけでも大成功な気がします。
私は授業が被っていて参加出来ていませんが、最近のゼミでもお披露目したところ、評判だったようです!
長期間かけて作った甲斐があって良かったです!
今後はドアへの設置方法や入れ込む写真について検討していければと考えています。
まだまだ、完璧に完成するまでには時間がかかりそうですね。
これからどうなっていくのかがとても楽しみです!!
以上、成果物のブログをmagがお送りしました。
最近更新されたブログ以下に載せておきますので、是非ご覧になって下さい!
こんにちは、小倉研4年のpeaceです。peaceの夏休み 第3回目は、北陸旅2日目の石川県について書こうと思…
こんにちは、ゆうです。 大学生の夏休みは小中高学生に比べ「長い」と言われていますが、なんだかんだで完全な休みが…
こんにちは、小倉研4年のpeaceです。peaceの夏休み 第2~4回目は、8/25~27で行ってきた北陸旅に…

みなさんは今話題の「Midjourney」をご存知でしょうか?
URL:https://www.midjourney.com/home/#about
Midjourneyとは、
Midjourney is an independent research lab exploring new mediums of thought and expanding the imaginative powers of the human species. We are a small self-funded team focused on design, human infrastructure, and AI. We have 11 full-time staff and an incredible set of advisors.
だそうです。英語は苦手なもので、難しかったので、翻訳にかけると
Midjourneyは、新しい思考媒体を探求し、人類の想像力を拡張する独立した研究室です。 私たちはデザイン、ヒューマンインフラストラクチャ、AIに焦点を当てた小規模な自己資金によるチームです。11名のフルタイムスタッフと、素晴らしいアドバイザーを擁しています。
とのことです。
私が実際に使ってみた結論からいうと「とてもすごいAI」です。抽象的な表現になりますが、使ってみるとわかっていただけると思います。
今回は「education」「education_technology」「technology_education」のキーワードで画像を生成してみました。


どれも「education」というキーワードで生成したため本の印象が強いように感じます。教育というのは明確な「モノ」ではないため、それぞれが抽象的な画像になっています。
番外として私の趣味である「nogizaka46」のキーワードで生成してみると

グループカラーである紫をもとに、人の画像があるものもあるので、学習しているのを感じます。
「AIが生成した画像の著作権はどこに帰属するの?」という疑問は当然出てくると思います。私は法律の専門家ではないため、一度ニュース記事を調べてみました。
https://www.itmedia.co.jp/news/articles/2208/09/news162_3.html
上のサイトにはアメリカでの対応と、現在の日本での現状が記載されていました。気になる方は是非とも読んでもらいたいと思います!
YoutubeのおすすめやGoogleの検索予測などAIは私達の身近なものになっています。「Midjourney」は絵を描くという。文化的な創作活動を行うAIになります。パラメータを変化させるとキーワードの強弱もつけることができます。色々試してみると、人間が絵を描く意味を考えさせられます。
このAIは今後の技術科にも入ってくる分野であるともうので、教材の一つとして使うのもいいのかもしれません!
こんにちは。小倉研3年のpeaceです。
大変お待たせしました! 2ヵ月ぶりですね( ´∀` )
「YouTube Data API v3 使ってみた!」の第2弾です!
「まだ第1弾を見てない!」という方はこの記事を読む前にこちらを↓
https://www.mogura-lab.com/783
それでは第2弾スタート!
1.Google Cloud Platform への登録
2.APIキーの取得
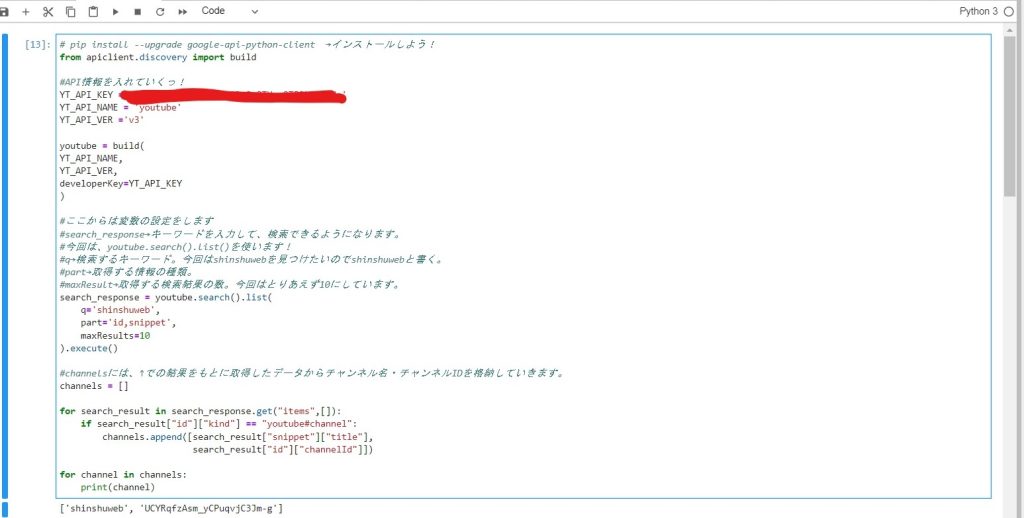
3.信州大学公式YouTube【shinshuweb】のチャンネルIDの取得
4.信州大学公式YouTube【shinshuweb】のいろんなデータ取得
2.APIキーの取得
3.信州大学公式YouTube【shinshuweb】のチャンネルIDの取得
今回は、前回登録した「Google Cloud Platform」から「APIキー」を取得していきます。
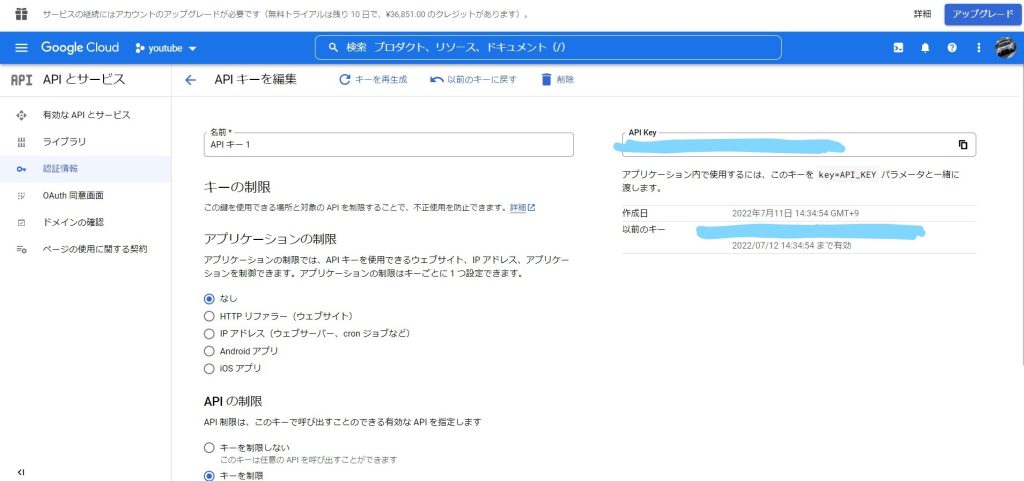
「APIとサービス」という場所から「認証情報」を選択するとAPIキーが取得できる画面にすすめます。
ここでAPIキーを取得するときに、画面下側の「APIの制限」で有効なAPIキーを今回利用する[Youtube Data API v3]のみに設定しておくとGoodです!
ここからは、信州大学の公式YouTubeである[shinshuweb]のチャンネルIDを取得していきたいと思います。
どのYouTubeチャンネルにも設定されている識別子(多くの対象の中から特定の1つを識別・同定するため用いられる名前や符号、数字等)のことです。
今回は、大量にあるYouTubeチャンネルの中から[shinshuweb]を見つける際にチャンネルIDが必要となります。
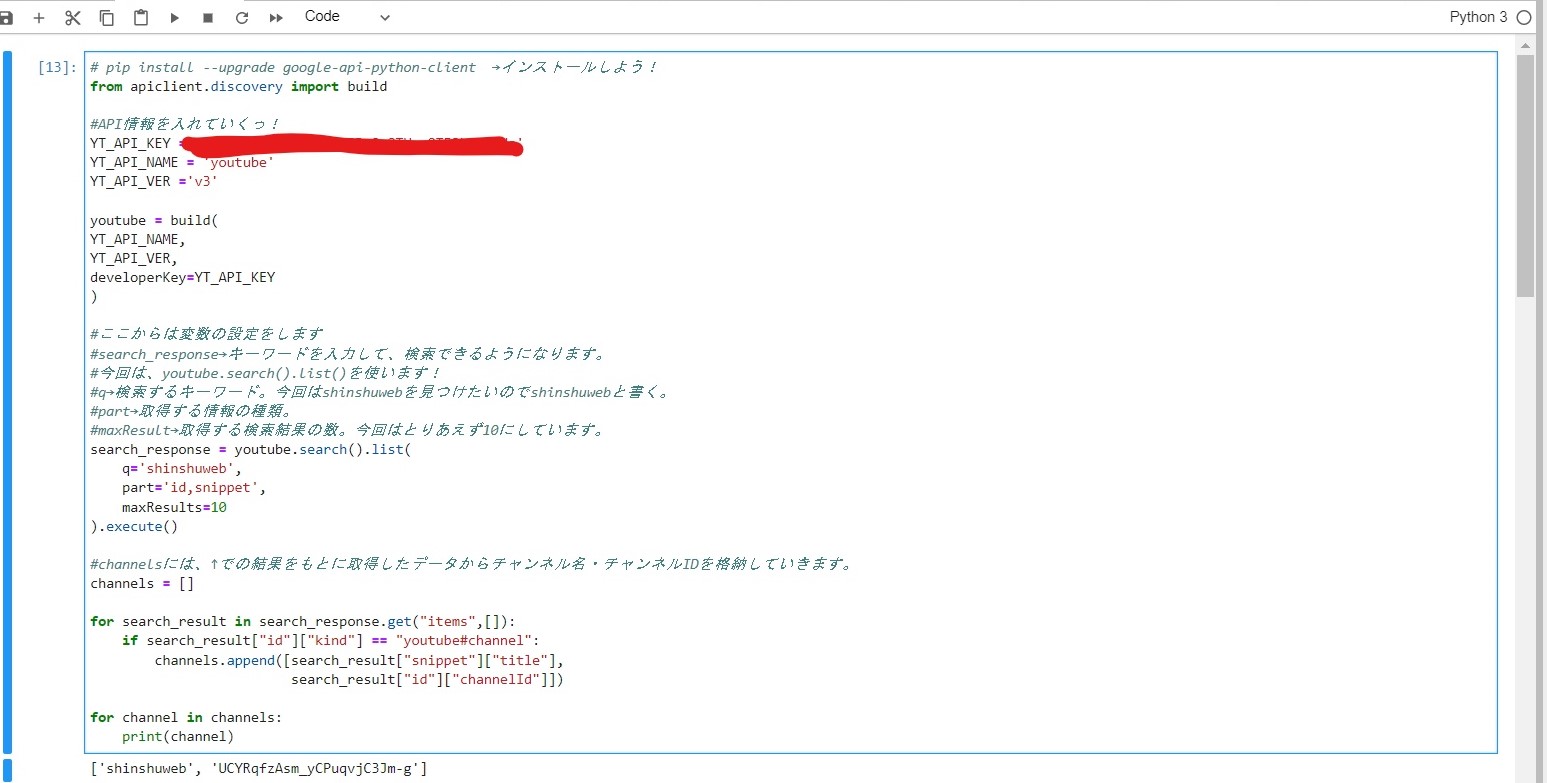
それでは、チャンネルIDの取得に使用したコードを載せておきます。
詳細は、コード中のコメントアウトを見てください。
次回からは、いよいよデータの取得をおこなっていきます!
しかし、Google Cloud Platformの体験期間が残り10日!
そして、今週末の3連休(7/16~18)が授業で全部つぶれるといった過酷なスケジュールなので、できたところまで載せる形になるかもしれません…
とりあえず、がんばるので次の投稿を待ってていただけたらと思います!
皆さんも、Google Cloud Platformの体験期間を使うときには計画的にご利用ください(笑)
最後までご覧いただきありがとうございました!

LINEのAPIを知っているでしょうか?現代ではLINEはほとんどのスマホユーザーが利用しています。1つのツールとしてLINEのAPIを知っていると課題解決の方法が広がると思います。今回はLINEのAPIの導入方法を紹介したいと思います。
LINEのAPIを活用すると本当にたくさんのことができるようになります。公式LINEの仕様を変更することや、チャットボットの作成、アンケート集計などなど多岐にわたります。もちろんこのようなシステムは複雑でレベルも高いです。しかし、「メッセージを送るだけ」なら簡単にできます。なので、制作活動の中で必要な機能を少しずつできるようになれば、いずれ複雑なものを作れるようになると思います。
「LINE API USE CASE」にはLINE が公式に公開しているAPIの活用法になります。レベルがとても高いですが、見てみると想像が膨らむと思います!
LINENotifyはご存じでしょうか?
LINENotifyというのは「Webサービスからの通知をLINEで受信するツール」です。もう少し詳しく解説すると「Webサービスと連携すると、LINEが提供する公式アカウント”LINE Notify”から通知が届きます。複数のサービスと連携でき、グループでも通知を受信することが可能です。」となります。
LINENotifyサイトはこちら
LINENotify API Documentはこちら
ここでは、Notifyの「サービスへの登録」→「送信するルームの選択」→「トークンの発行」までを行いたいと思います。
LINENotifyのサイトはこちら
import requests
TOKEN = 'トークンをペーストしてください'
url = 'https://notify-api.line.me/api/notify'
send_contents = 'LINE大好き'
TOKEN_dic = {'Authorization': 'Bearer' + ' ' + TOKEN}
send_dic = {'message': send_contents}
requests.post(url, headers=TOKEN_dic, data=send_dic)このコードを実行すると、先程決めたトークルームに「LINE大好き」と送られます。また、少しコードを増やすと画像も一緒に送信できるので、やってみてください!
この方の動画がとてもわかりやすいので、参考になると思います。
前のブロックでは「LINENotify」を扱いました。これは簡単に使えるので、とても便利な反面、できることにどうしても制約があります。今回紹介する「LINE Messaging API SDK」ではできることが格段に増えます。
できることの一例
LINECLOVAなどのAIとの 連携
LINEミニアプリでの活用
LINEPay決済ツールとの 連携
他サービスとLINEログインの連携
MessagingAPIを活用し双方向性のコミュニケーション
などなど、LINEサービスを使い尽くすことができます。
もちろん言語もほとんど網羅されいて、GitHubでAPIリファレンスが公開されています。URLはこちら
MessagingAPIではLINENotifyとは異なり、より多くの人にメッセージを送信でき、双方向性があるので、チャットボットの作成やAIも組み込むことができたら面白そうですね!
まだ、わからないことが多く、導入例などは今回は紹介しないのですが、今度作成したら紹介したいと思います。
今回はLINEのAPIサービスの紹介を行いました。「LINENotify」は簡単に導入できるので、一度試してみる価値は全然あると思います!また、MessagingAPIもメッセージを送信するだけなら難しくはなく、Youtubeの動画などを参考にしたら活用できると思います
また、LINEのビジネス用アカウントでは、メッセージ配信もできるので、チャックしてみるのもアリかもしれません。
今回のブログを通じて、LINEのAPIサービスを使うきっかけになればと思います。
どうも。magnetです。
最近の情報系の授業において、「スクレイピング」というものを学びました。
スクレイピングについて詳しく知りたい方は、
「ゆう」が書いたこちらの記事をどうぞ~
その授業で各自製作の課題が課されたので、
とあるサイトをスクレイピングしてみました!!
以下に私が書いたコードを載せておきますね~。
import requests
from bs4 import BeautifulSoup
# importでrequestとbs4のBeautifulsoupを読み込みます。
# Webページを取得して解析する
load_url = "とあるサイトのURL"
# とあるサイトのURLをload_urlと定義。
html = requests.get(load_url)
# htmlをrequestのgetというメソッドを使い、 するものだと定義する。
soup = BeautifulSoup(html.content, "html.parser") # HTMLを解析する
#ちょっとよく分からない。
# ~ここまでで、HTML全体を表示するプログラムは完成~
menu_all = soup.find_all(class_ = "menu-list")
# menu_allと定義します。
for menu in menu_all :
#for 関数 in リスト でmenuの中にmenu_allを何回も入れていきます。
menu_name_full=menu.find_all('h4',attrs={'class':'menu-name'})
#menu_nameを全て探すことを、menu_name_fullと定義します。
for menu_name in menu_name_full :
#menu_nameの中にmenu_name_fullを何回も入れていきます。
print(menu_name.text)
print()
#printで指定したものの表示と、見やすいように空白を表示しています。それぞれのコードの詳しい説明は#で書いてある文を参照してみて下さい!
これを実行すると、、、
メニュー一覧が出てきます。。

やってることそんなに難しそうじゃ無いじゃんか。
って思うかもしれませんが、
実際やってみると結構重めです……
なかなか理解出来ずに困ってましたが、
周りの助けも有りなんとか完成できました!
手伝って下さりありがとうございました。
今回のものは、メニュー一覧だけの表示となっていますが、
カロリーや値段も対応して表示出来ると、
データサイエンスみが増しますね。
また、完成したら投稿したいと思います。
ではでは。
あ、あと興味があればぜひ最新の投稿もご覧下さい!