おしながき
- 今回やりたいこと
- 作る順番
- ライブラリのインストール
- コーディング
- Pandasを使って、CSV形式での保存
- まとめ
今回やりたいこと
今回やりたいこととしては、
学校情報サイトから、「学校名」「生徒数」「住所」をスクレピングしていきたいとおもいます。そして、最後にはPadansを使って、CSV形式で保存するところまでやっていきたいと思います。
順序は
- ライブラリのインストール
- コーディング
- Pandasを使って、CSV形式での保存
大まかに分けてこの3つになります。少し長くなってしまうかもしれませんが、ゆっくりやっていきましょう!
作る順番
1.ライブラリのインストール
今回使用するライブラリは「requests」「Beautifulsoup 」「pandas」「time」の4つです。webスクレイピングというと「selenium」もBeautifulsoup と同様に人気で使われていますが、今回は使用しないです。
インストールを行っていない方は
pip install requets
pip install pandas
pip install Beautifulsoup
をコマンドプロンプトでやっていただければインストールをできます。
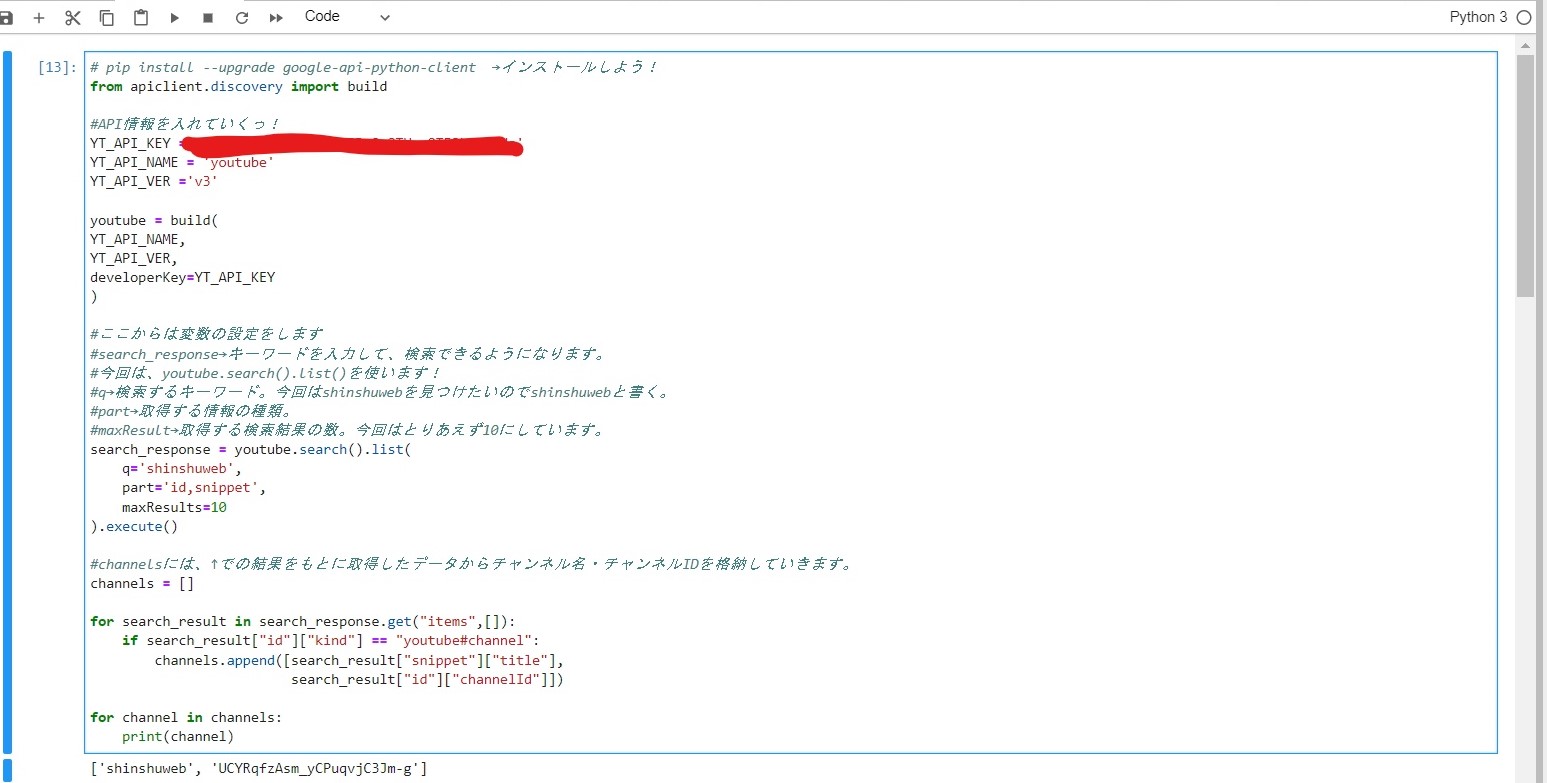
2.コーディング
下のものが本編になります
#今回使うライブラリ
import time
import requests
from bs4 import BeautifulSoup
import pandas
#スクレイピングをするサイト
#URLは今回は伏せておきます
url='@@@@@@@@@@@@@@@@@@@@@@@@@@@'
#requestsを使って、URL先の情報を取得
res=requests.get(url)
soup=BeautifulSoup(res.text,'html.parser')
school_list=soup.find_all('li',attrs={'class':'school_list_city'})
for details in school_list :
school_details={}
sdd=details.find('div',attrs={'class':'school_detail_data'})
school_name=sdd.find('p',attrs={'class':'school_name'}).find('span').text
shcool_item=sdd.find('p',attrs={'class':'item'})
total_students=shcool_item.find('span',attrs={'class':'border_underline'}).text
ads=sdd.find('p',attrs={'class':'item position'})
ad=ads.find('span',attrs={'class':'small'}).text
school_details['学校名']=school_name
school_details['生徒数']=total_students
school_details['住所']=ad
data.append(school_details)
time.sleep(2)
コードがきれいに書けていないかもしれませんが、まだまだ勉強中の身なので、ご容赦していただければと思います
少し解説をさせていただくと
ところどころに「~.find(‘@@’),attrs={‘class’:’%%%’}」と言った記述がたくさんあると思います。これを抑えることができたら簡単なスクレイピングは可能かと思います。
これを日本語変換してみると「~の中の一番最初の@@タグのclassの%%%を指定します!」といった感じです。HTMLというデータはとても大きいものなので、一気に操作を行うのではなく、少しづつ絞っていくとやりやすいのではないかと思います。
3.Pandasを使って、CSV形式での保存
スクレイピングをしたデータをpandasを使って、DataFrameに格納し、それをCSV形式で保存することは一見難しそうに見えますが、案外簡単です。
#pandasを使って、DataFrameに格納
df=pd.DataFrame(data)
#CSV形式で保存
df.to_csv('学校の情報.csv',index=False,encoding='utf_8_sig')
この2行だけで終わりです。少し解説をさせていただくと、「index=False」というのは、DataFrameに格納した際にインデックス番号が同時に付与されるのですが、「CSV形式で保存するときにそのインデックス番号はいらないよー」ということです。
まとめ
かなり駆け足でBeautifulsoup を使ったWebスクレピングを紹介していきました。高校情報Ⅱの教員研修資料にも今回のBeautifulsoup を使ったWebスクレイピングは紹介され、今後必要なスキルの一つになるのではないかと思います。
また、プログラミングは様々な勉強ツールがあります。今回は私が勉強するときに使用したYouTubeの動画のURLを載せておきたいと思います。勉強するときの助けになればいいなと思います。